
作者介绍:张昊阳,国民手游游戏技术策划、前AI赛道创业者,5年AI领域从业经验,7年游戏开发经验,AIGC+游戏探索和布道者。
本文尝试围绕AIGC在游戏领域的应用这一话题,为读者提供“走马观花”式的阅读体验,分享行业见闻而非着重介绍晦涩技术概念、细节,抛砖引玉,启发思考,将针对以下四个主题进行分享:
一、AIGC在游戏领域的基础应用
提取作者了解到的AIGC+游戏基础应用,从游戏工业的不同侧面梳理AIGC带来的生产力革命、创新可能性
二、AIGC在游戏领域的上层应用
以具体案例简要探索AIGC在游戏领域的上层应用,如AI NPC、虚拟人、数字人社群,聚焦综合解决方案
三、AIGC热点话题
探讨AIGC在游戏领域的技术瓶颈、法律风险、伦理争议等,帮助读者补全相关视野
四、“全要素生成”——AIGC+游戏未来展望
从作者个人视角探讨AIGC引发游戏形态革命的可能性,畅想科幻电影中的情境何时照进现实

AIGC定义:AIGC即AI Generated Content,又称生成式AI,即人工智能生成内容。在量子位《AIGC内容产业展望报告》 中,将AIGC定义为基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数据寻找规律,并通过适当的泛化能力生成相关内容的技术。与之相类似的概念还包括Synthetic media,合成式媒体,主要指基于AI生成的文字、图像、音频等。Gartner也提出了相似概念Generative AI,也即生成式AI。生成式AI是指该技术从现有数据中生成相似的原始数据。相较于量子位智库认为的AIGC,这一概念的范围较狭窄。
AIGC本质上是一种AI赋能技术,可以通过高通量、低门槛、高自由度的生成能力,广泛地服务于各种内容生产行业,它不单单是继PGC、UGC之后的新的内容创作形态,也不仅限于降本增效,而是能创造额外价值的、具有快速增长潜力的细分赛道。如在游戏《骑马与砍杀》中,接入ChatGPT的API可以实现更为拟真的AI NPC对话能力;在游戏《AI Dungeon 2D》中,玩家可以同时享受AI生成的故事文本和对应图像;在CG软件Wonder Studio中,用户可以导入一段视频通过AI生成对应的CG画面,乃至将动作导入游戏引擎再次加工。AIGC赛道在过去数年间迎来了井喷式发展,在部分领域的表现已经超越人类。
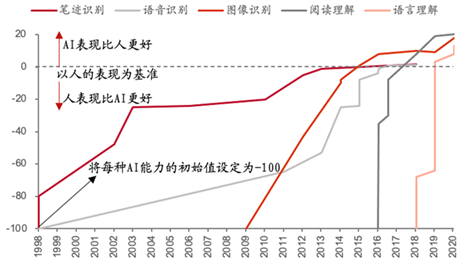
图:目前AI在部分领域表现已经达到人类标准 来源:Our World in Data,中泰证券研究所
在过去的2022年,一些现象级AIGC产品成功破圈,从Midjourney、Stable Diffusion再到ChatGPT——AIGC相关公司正如雨后春笋般涌现,相关岗位需求猛增。脉脉的数据显示,近三年AIGC领域的人才持续增长。

图:AIGC相关公司Landscape 来源:2023 data, ML and AI landscape: ChatGPT, generative AI and more

图:AIGC行业相关岗位增长势猛 来源:脉脉高级人才智库
一、AIGC在游戏领域的基础应用
下文将从文本、图像、音频、视频、三维、策略等六个模态,综合介绍AIGC在游戏领域的基本应用。跨模态/多模态内容没有单独列出,将融合在此六个模态下穿插介绍。笔者认为,跨模态/多模态能力将是未来最具潜力和价值的发展方向。

首先是文本和图像两大模态,22年这两个模态诞生了诸如ChatGPT、MidJourney、Stable Diffusion等现象级产品,也进一步整个社会推动了相应领域的研发激情和实际投入。如文本领域,语言模型及产品在ChatGPT爆火后迎来了一波井喷,如Newbing、Claude、Meta LLaMA、斯坦福Alpaca、国内的清华系公司智谱科技研发的ChatGLM、复旦MOSS、百度的文心一言、阿里通义千问等。
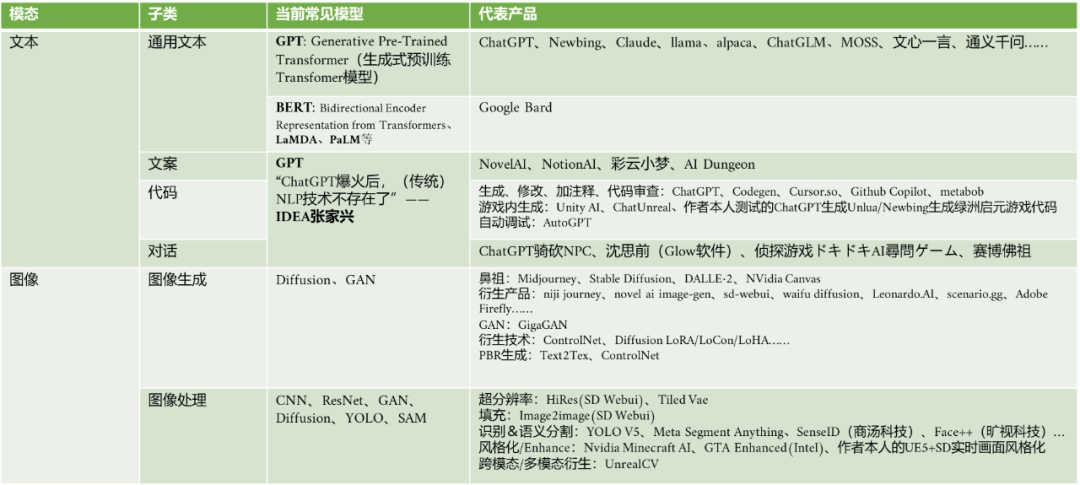
文本生成并不是只有大众熟知的GPT生成式预训练Transformer模型一种解决方案,此前谷歌的BERT(Bidirectional Encoder Representation from Transformers,什么是BERT?),LaMDA和它对应的产品Bard,以及其他的NLP技术已有多年积累,GPT则是迄今为止效果最好的一种解决方案,关于这一点IDEA张家兴博士有个圈内知名度较高的调侃——“ChatGPT爆火后,NLP技术不存在了” 。
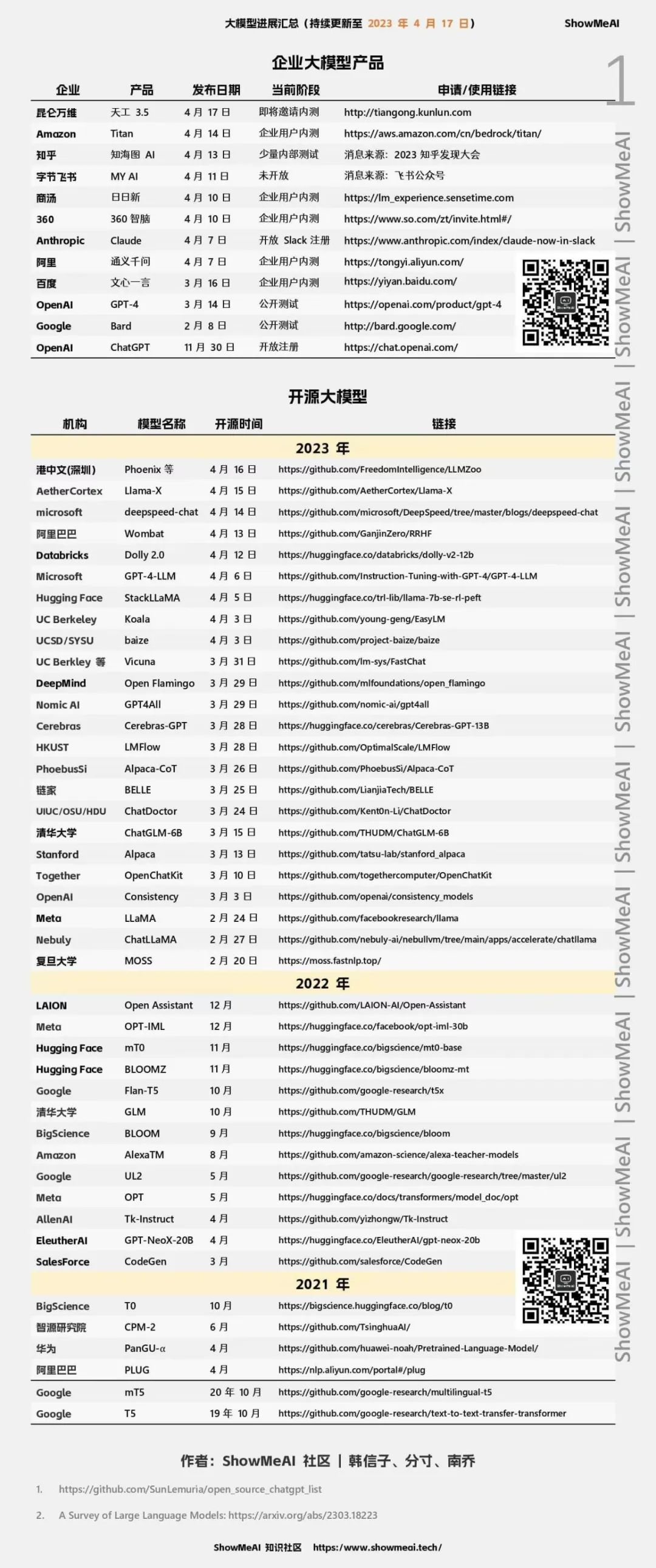 图:大模型进展汇总 作者:ShowMeAI社区 | 韩信子、分寸、南乔
图:大模型进展汇总 作者:ShowMeAI社区 | 韩信子、分寸、南乔
笔者将文本生成在游戏中的应用分为通用文本、文案、代码、对话等四个子类。
文本生成
通用文本更贴近应用文本和泛文本类型的生成,如游戏策划案设计思路、设计细节、游戏里用到的表格、游戏本地化内容、乃至数据分析输出报表,都属于通用文本的范畴。
 图:ChatGPT输出卡牌游戏策划案
图:ChatGPT输出卡牌游戏策划案
 图:ChatGPT输出战争类游戏伤害公式
图:ChatGPT输出战争类游戏伤害公式
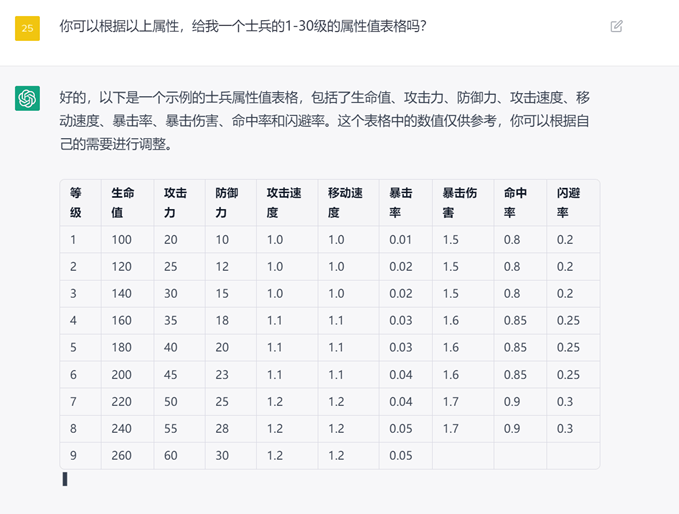 图:ChatGPT输出角色属性值表格
图:ChatGPT输出角色属性值表格
文案方面,游戏里的故事文本、对话数据(这里指预设好的对话,而不是交互式生成的对话文本)等均可以通过NovelAI、NotionAI、彩云小梦等工具生成,乃至产生新玩法,如AI Dungeon,它可以动态生成故事,且能够根据玩家的输入做出反应,生成不可预测的动态游戏体验。最新的GPT技术撰写的文案在某些情况下能超越人类水平,尤其是在一些限定的规则下,如只使用某些特定的字母、Emoji,或是编写藏头诗等等。

图:ChatGPT补全故事
 图:ChatGPT使用Emoji表达指定的内容
图:ChatGPT使用Emoji表达指定的内容

图:ChatGPT写诗称赞嘉然
代码方面,在游戏制作过程中可以用Copilot、Cursor这类IDE工具或者插件辅助游戏开发,代码审查则有Metabob提供能力支持,也可以通过将GPT接入游戏引擎,接管关卡内容创建逻辑(跨模态),乃至游戏运行时生成游戏代码和游戏内容。笔者也测试过使用ChatGPT生成Unreal Engine引擎里的简单交互逻辑,及NewBing生成和平精英绿洲启元的代码等,认为具备一定的可行性和想象空间。
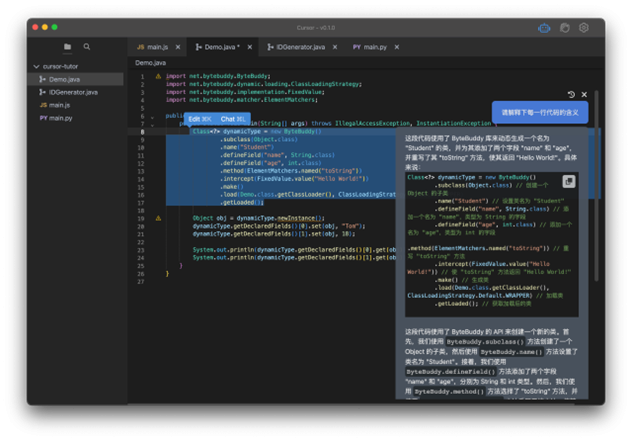 图:Cursor.So软件,它可以帮助你生成和调试代码
图:Cursor.So软件,它可以帮助你生成和调试代码
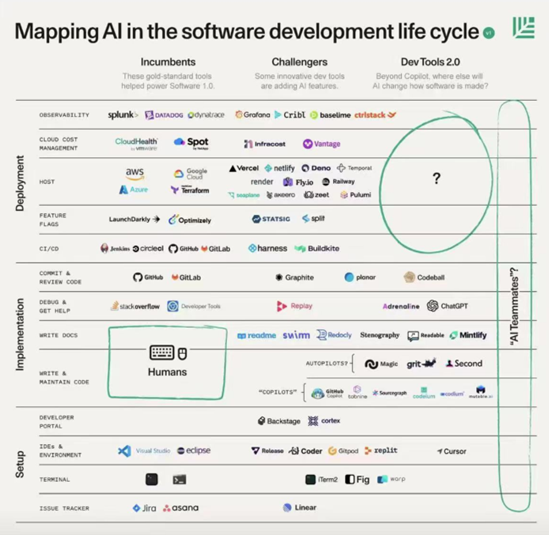
图:Mapping AI in the software development life cycle - 软件开发领域的AI工具Landscape
交互式文本生成(对话生成)方面,早年即有相关应用,如微软小冰,但受限于以往NLP技术的生成,没有大量应用在游戏中用作角色扮演,GPT的出现改变了这一局面,如前文介绍到的《骑马与砍杀》ChatGPT NPC,Glow软件里的虚拟人沈思前、日本小程序赛博佛祖,都是让GPT驱动的AI扮演一个特定角色。新的玩法也在产生:如侦探游戏《ドキドキAI尋問ゲーム》让玩家扮演侦探审问犯人,审问的“犯人”接驳ChatGPT,玩家需要在7次对话内让AI犯人说出“我是犯人”来通关游戏,思路让人眼前一亮。
 图:《骑马与砍杀》ChatGPT NPC
图:《骑马与砍杀》ChatGPT NPC
 图:侦探游戏《ドキドキAI尋問ゲーム》需要玩家在7次对话内让AI犯人说出“我是犯人”
图:侦探游戏《ドキドキAI尋問ゲーム》需要玩家在7次对话内让AI犯人说出“我是犯人”
图像生成
在图像生成领域,MidJourney、Stable Diffusion、DALL·E 2等工具已让大众耳熟能详且成为了这一领域的鼻祖,现如今则发展成了MidJourney和Stable Diffusion二分天下的局面:艺术家/设计师更偏爱MidJourney,因为它生成的内容质量足够高且相对易用,工程师/技术美术和大厂则更偏爱Stable Diffusion,因为它可以输入复杂的参数来进行精细化控制且代码开源。
 图:Midjourney AI vs Stable Diffusion - Which generate BETTER Images?
图:Midjourney AI vs Stable Diffusion - Which generate BETTER Images?
与Stable Diffusion相关的最著名开源项目便是由AUTOMATIC1111开发的Stable Diffusion web UI,几乎一半以上的Stable Diffusion使用者都在使用此工具或是为其开发新的开源能力,使其愈发强大。伴随着生态的发展,Dreambooth、LoRA、LoCon、LoHA等Diffusion Model微调方案相继出现,ControlNet则将用户对生成图像的控制力提升到了一个新的高度。基于Stable Diffusion的商业工具如NovelAI Image Generator、Leonardo.AI、Scenario.gg也开始出现,并应用在游戏原画、场景、图标设计等领域。值得一提的是,著名数字艺术工具公司Adobe也加入了战斗,推出了自己的AI生图工具Firefly。
 图:NovelAI Image Generator的推出将AI绘画的发展推向了一个新的高潮
图:NovelAI Image Generator的推出将AI绘画的发展推向了一个新的高潮
 图:Leonardo.AI集成了Stable Diffusion的各种能力,简化了使用繁琐度
图:Leonardo.AI集成了Stable Diffusion的各种能力,简化了使用繁琐度
AI生成图像对游戏原画领域的提效和冲击无疑是巨大的,一个比较经典的案例是《猴子都能学会的AI角色设计》(2022年Q3),作者演示了如何使用AI绘画工具将一个大头涂鸦一步步转化成完整的角色设定。事实上,AI绘画被大量一线游戏大厂的许多项目组普遍采用来提升沟通和创作效率已经是一件众所周知的事。

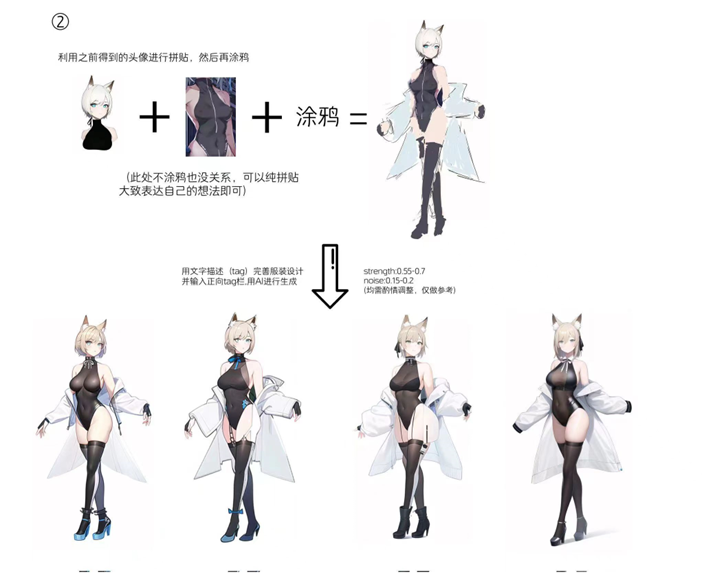
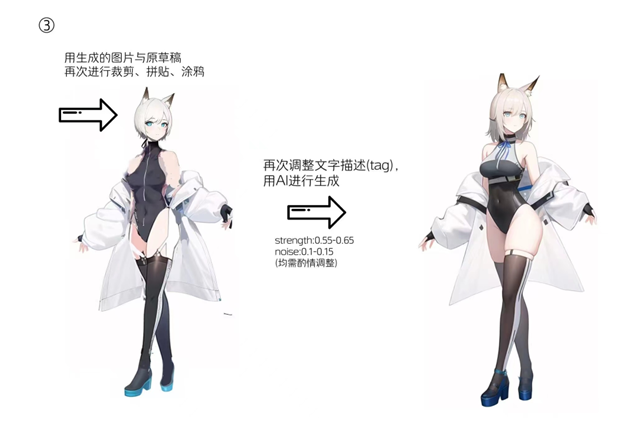
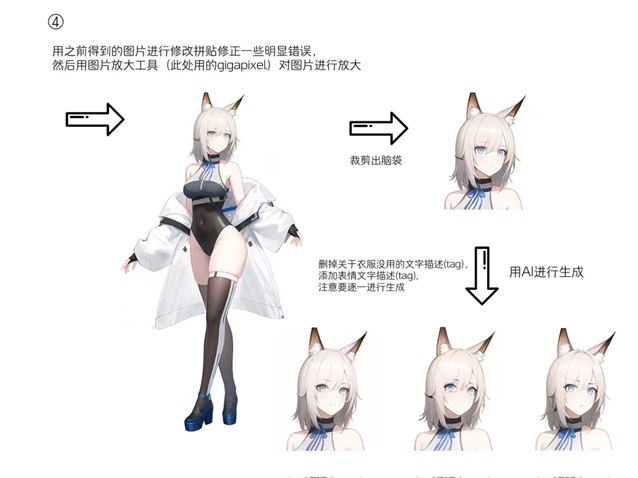
 组图:猴子都能学会的AI角色设计
组图:猴子都能学会的AI角色设计
不单单是原画领域,在游戏贴图生成与处理、游戏实时画面增强/风格化、浮雕/卡雕效果乃至全景图到3D场景的生成方面,AIGC的运用也已屡见不鲜。如Text2Text使用Diffusion算法提供了从白模生成贴图的解决方案、Poly可以用自然语言prompt生成PBR材质球,Nvidia的Real-Time Neural Appearance模型甚至可以实时生成效果极惊艳的电影级别的写实外观材质。在游戏《Tales of Syn》中,作者用了Stable Diffusion的深度图生成能力,结合游戏引擎的曲面细分能力制作了3D卡雕效果、笔者也曾尝试使用ControlNet与UE5引擎结合,对UE5渲染的图像进行实时风格化处理。而AI的超强参数化生成能力,让一些此前不可能实现的玩法变得可能,如使用LoRA模型固定风格和角色的方法,在游戏运行时提供批量生成指定形象的能力,实现“千人千女”或是“千人千宠”。
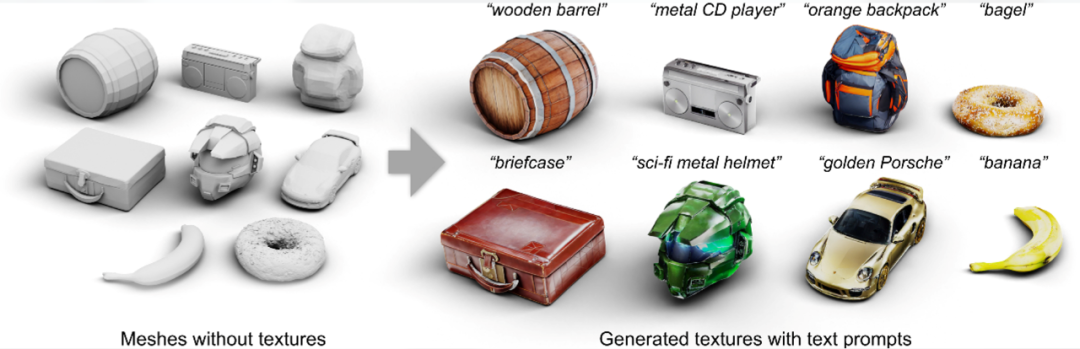
图:Text2Tex提供了从白模生成贴图的解决方案
 图:Poly可以用自然语言prompt生成PBR材质
图:Poly可以用自然语言prompt生成PBR材质
 图:nVidia提出可达电影级别的,实时神经外观生成模型,支持各向异性采样和LoD渲染,shader速度相比之前快一个级别,效果极惊艳
图:nVidia提出可达电影级别的,实时神经外观生成模型,支持各向异性采样和LoD渲染,shader速度相比之前快一个级别,效果极惊艳

图:Tales of Syn使用Stable Diffusion的能力制作卡雕效果
 图:作者本人制作的ControlNet+UE5实时风格化渲染案例
图:作者本人制作的ControlNet+UE5实时风格化渲染案例
除此以外,交互式生成也是一个值得游戏从业者关注的生成方式,NVIDIA推出的Canvas应用可以让使用者通过涂鸦的方式实时生成指定风格和内容的图像,在一款名叫Unstable Journey的开源应用中也提供了类似的交互形式,这不禁让人联想,是否可以用AIGC的方式制作一款升级版的“你画我猜”。
 图:Nvidia Canvas应用程序
图:Nvidia Canvas应用程序
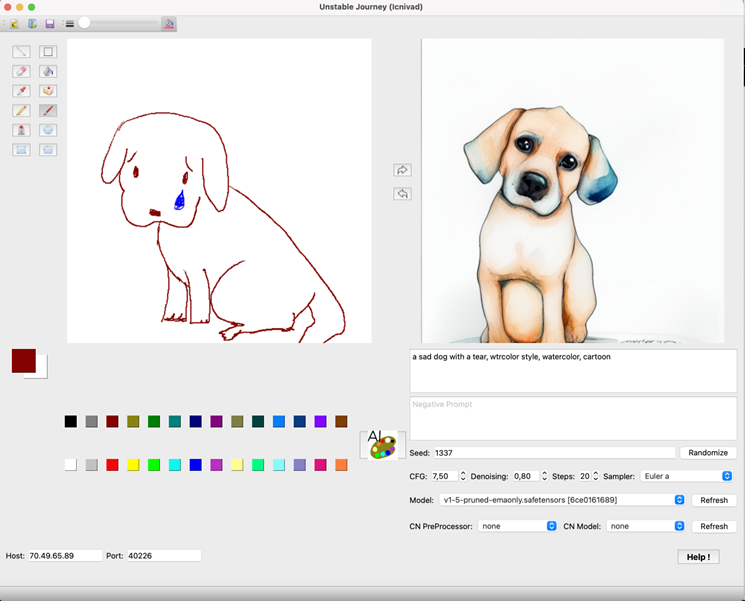 图:Unstable Journey应用
图:Unstable Journey应用
由此我们可以推断,AI生图能力在未来将更多地集成在游戏程序中,成为玩法不可分割的一部分。而在图像处理方面,AI也表现了超乎想象的惊人实力,无论是超分辨率还是语义分割,相关领域已发展多年,在近期又迎来了新的突破,在最新的一篇论文《Segment Anything》中,Meta发布的语义分割模型SAM让不少人惊呼“CV(计算机视觉)不存在了!”无独有偶,前不久Meta更是推出了其多模态模型ImageBind,这是一个能够同时绑定六种模态数据的AI模型,使得机器能够更好地分析多种不同形式的信息。类似的应用也被运用在了游戏生产管线中,例如UnrealCV就提供了一种在Unreal游戏引擎中识别3D物体并生成深度、法线等信息的解决方案。
 图:Meta发布的语义分割模型Segement Anything(SAM)
图:Meta发布的语义分割模型Segement Anything(SAM)
 图:UnrealCV提供游戏引擎内的计算机视觉能力
图:UnrealCV提供游戏引擎内的计算机视觉能力
音频生成

音频和视频内容生成也是游戏内容生成中不可忽视的一部分。从AI作曲到声音克隆,AI生成的音频已然出现在许多游戏作品和游戏二创内容中。早在2016年,一款名为AIVA的AI作曲工具就曾掀起过一波浪潮,此后的AI作曲工具层出不穷,如Mubert、Jukebox、Melodrive等,虽然AI作曲的质量与人类艺术家的作品仍有一定差距,但在一些低成本、小制作的游戏中,这类“罐头音乐”内容能够以低成本、高效率的优势取代人工作曲,完成配乐需求。
声音克隆(又称音色迁移)则是近年非常流行的一种语音合成技术。相较于传统语音合成中生硬的机械音,声音克隆一经推出便以其媲美真人的音色全面占领市场。在声音克隆中,主要有两类突出的应用:歌声合成、人声合成。歌声合成技术目前已经趋于成熟,下面的案例展示了在up主的“调教”下,将周杰伦的音色迁移到日本歌手Aimer的名曲《カタオモイ(单相思)》中,不但还原了天王巨星的音色,连吐词不清的慵懒感也一并迁移,十分震撼。
 图:AI周杰伦演唱Aimer名曲カタオモイ(单相思)
图:AI周杰伦演唱Aimer名曲カタオモイ(单相思)
人声合成方面,技术尚不如歌声合成成熟但仍值得期待。如在下面的视频中,up主展示一个了用Vits的开源解决方案,将原神派蒙的语音作为语料进行训练合成的“AI派蒙”,不难感受到,尽管真人配音在情绪表达方面完胜AI合成音,AI依然能把语气、抑扬顿挫等人类特点学习并复现出来,在一些独立游戏中,这类合成音或许能在让玩家接纳的前提下节约成本、提高配音效率。在一些游戏二创内容中,此类应用也已屡见不鲜,遑论铺天盖地般使用AI合成音配音的各类短视频。
 图:魔音工坊AI合成音
图:魔音工坊AI合成音
视频生成
在图像生成技术蓬勃发展并成功破圈后,视频生成的能力也接踵而来,引发诸多关注。视频生成有几种不同的形态,如从文本生成、从给定的图像生成、从视频生成等,虚拟人生成由于其独特的应用场景和技术路线,笔者将单独拆分出一类进行介绍。
从文生成的经典案例和应用有Runway Gen-2和NVIDIA VideoLDM,它们均可以用给定的一串描述文本生成一系列画面并组成序列帧。
从图生成的案例比较出名的则是今年早些时候由著名影视制作团队Corridor Crew团队发布的视频《石头剪刀布(VFX Reveal Before & After - Anime Rock, Paper, Scissors)》,它呈现了一种将拍摄的内容经由AI生成图像和影视后期的方式加工为动画的可能性,发布后引发了CG圈的巨大讨论,影响了后来的诸多创作者。再如使用类似手段制作的一系列MMD视频内,将原本3D渲染的画面通过AI生成的方式重新加工成手绘风格,也有着一定数量的拥趸。

图:MMD嘉然,AI动画,作者大江户战士@哔哩哔哩
针对这一特定应用场景,目前已经有相对成熟的解决方案,如Ebsynth、mov2mov(基于stable diffusion)等。均能提供具备一定稳定性的图生视频、视频生视频解决方案。而在视频生视频方面,WonderStudio则提供了一种不一样的解决思路——将实拍的人像视频提取动作,抠像并合成CG画面,提取的动作甚至可以导入游戏引擎中再次处理和使用。不妨畅想一下,倘若未来将此类技术运用在AR游戏中,创造出的独特游戏体验或堪比科幻剧情。
需要特别指出的一类应用场景是虚拟人视频合成,虚拟人目前在国内外已经是一个相对独立的细分赛道,有着不同的技术路线。虚拟人视频合成则是一类通过驱动指定图像,或是给已有视频换脸的方式来生成相应的视频内容。比较知名的解决方案有MegaPortraitsAI、SadTalker、D-ID、HeyGen等。受限于视频生成的特性,往往此类解决方案的弊病是缺乏肢体语言,易触发恐怖谷效应。
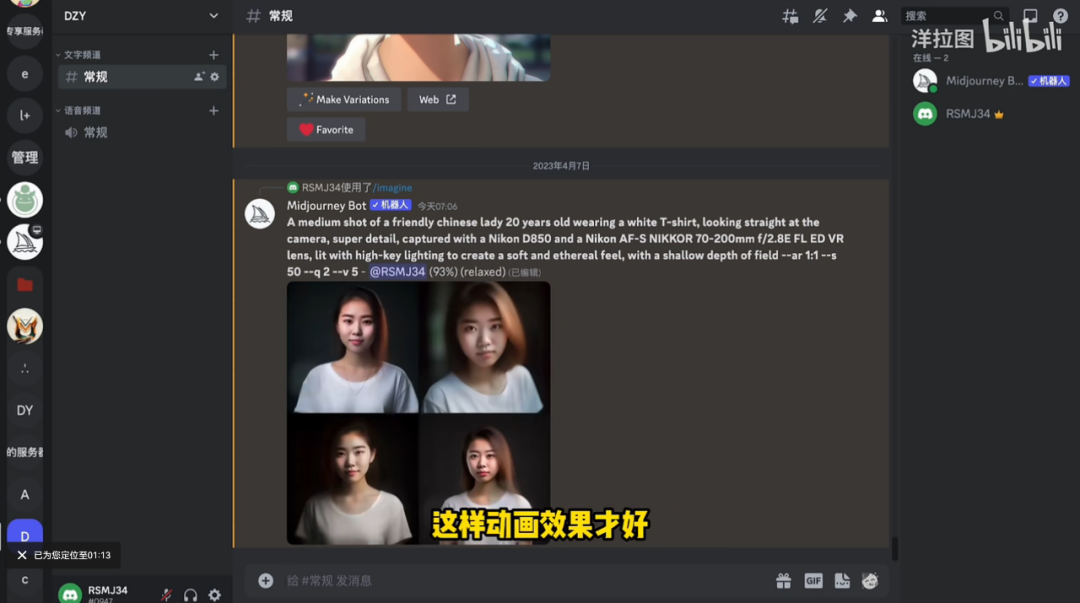 图:Midjourney + D-ID + ChatGPT生成虚拟人
图:Midjourney + D-ID + ChatGPT生成虚拟人
此外,视频生成中并不能被忽视的一部分是AI视频处理,如老牌的AI处理工具Topaz,提供了视频修复、抠像、超分辨率等一系列能力。而近期发布的一篇论文《Segment Everything Everywhere All at Once》介绍的SEEM则将视频语义分割的能力推向了一个新的巅峰。
 图:华人团队研发的视频语义分割模型SEEM,将该领域的能力推向了一个新的巅峰
图:华人团队研发的视频语义分割模型SEEM,将该领域的能力推向了一个新的巅峰
三维生成
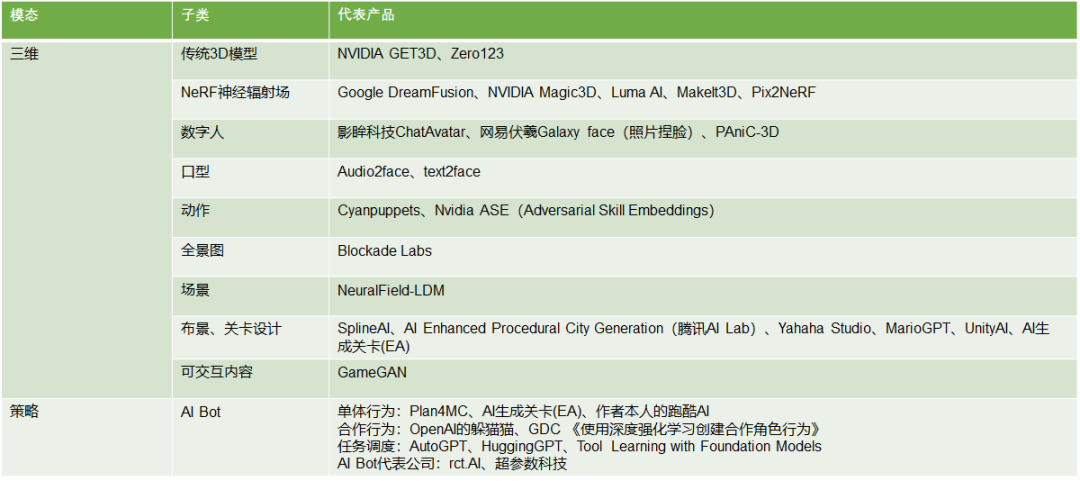
介绍完视频生成,我们再来看最后的两个模态:三维生成和策略生成。
三维生成方面,笔者将其分为模型生成、神经辐射场、数字人、动作生成、全景图、场景生成、自动化布景/关卡设计等。其中模型生成又分为传统3D模型生成和神经辐射场两种不同解决方案,传统3D模型生成即生成由点线面构成的、记录几何信息的模型,通常需要3D/深度监督来进行姿态估计。神经辐射场(NeRF)生成则是一种新兴的自监督生成方式,只需要图像和姿态来学习场景,具有照片真实感。
 图:NVIDIA GET3D三维重建解决方案
图:NVIDIA GET3D三维重建解决方案
传统3D模型生成中,NVIDIA GET3D提供了具有高保真纹理和复杂几何细节的3D形状生成方案,Zero123则利用Diffusion模型的特性,提供了从单帧图像生成3D内容的解决思路,OpenAI也在前不久发布了自己的3D生成解决方案shap-e,支持文生3D、图生3D。此外,传统的摄影测量技术也已经非常发达,广泛地运用在测绘和写实游戏资产生成的场景中。如在游戏《黑神话:悟空》中就大量运用了摄影测量技术来还原真实场景下的历史古迹、雕塑等。
 图:《黑神话:悟空》中存在大量数字雕塑,原型多为国宝级雕塑
图:《黑神话:悟空》中存在大量数字雕塑,原型多为国宝级雕塑
NeRF方面,Google DreamFusion、NVIDIA Magic3D都提供了较为完备的从文本生成3D信息(Text to 3D)的解决方案,微软MakeIt3D、Pix2NeRF则提供了从图像生成(Pix to 3D)的思路——即从单帧静态图像脑补成完整的3D模型的生成方式。Luma AI)则是NeRF生成领域的一个集大成者——不但上线了文生3D、视频生3D、网页版全体积NeRF渲染器,甚至在近期推出了将NeRF导入到UE5引擎中显示的代码插件,使得游戏开发者也可以使用NeRF作为资产进行游戏创作。
 图:Google DreamFusion
图:Google DreamFusion
在3D生成中,数字人是一个不容忽视的特殊应用场景。区别于视频驱动的虚拟人,3D数字人拥有一个或从骨骼、或从BlendShape驱动的三维模型,可以从多个角度高保真地模拟真人进行表演,现如今被大量应用在游戏和影视工业管线中。除Epic提供的MetaHuman解决方案外,网易伏羲实验室提供的Galaxyface能力(应用于游戏《永劫无间》)、影眸科技的ChatAvatar产品则分别从图生3D头模、文生3D头模两个侧面提供了跨模态实现思路。而在二次元模型生成中,脱胎于字节跳动A-Soul团队的PAniC-3D则提供了一种较为完备的VRoid模型生成方案。
 图:伏羲实验室的Galaxy Face能力已被应用于多款网易研发的游戏中
图:伏羲实验室的Galaxy Face能力已被应用于多款网易研发的游戏中
 图:上科大、影眸科技的ChatAvatar产品提供了从文本生成3D头模的能力
图:上科大、影眸科技的ChatAvatar产品提供了从文本生成3D头模的能力
 图:字节跳动PAniC-3D论文一瞥
图:字节跳动PAniC-3D论文一瞥
而驱动数字人的关键在于口型和动作的生成,相关领域已有多年积累。口型方面目前有两条较为成熟的技术路线:audio2face(语音生成口型)、text2face(文本生成口型)。动作生成方面,区别于传统的光学动作捕捉(如Vicon)和惯性动作捕捉(如诺亦腾),从视频生成动作随着人体姿态估计技术的愈发成熟,结合其相对低廉的成本,也开始受到一部分游戏厂商的青睐,占有一席之地,如国内公司青色木偶的CYANPUPPETS 2D引擎,海外公司MOVE Ai(曾服务EA)等。
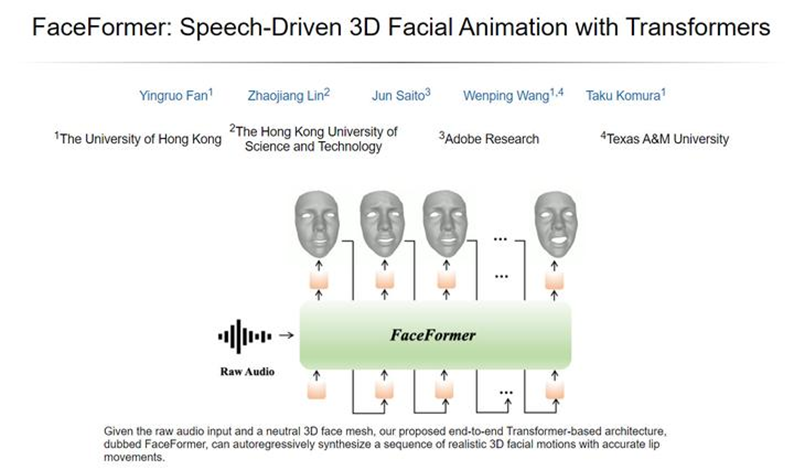 图:FaceFormer: 基于Transformers的,语音驱动的3D人脸动画生成
图:FaceFormer: 基于Transformers的,语音驱动的3D人脸动画生成
动作生成的另一条路径是使用对抗模仿学习、无监督强化学习等方法,让拥有人形Pawn的角色从大量非结构化(无需任何特定的标注或分段)的动作数据中试错,使角色能够自动合成复杂且自然的动作“策略”,以达成任务目标。一个具有代表性的案例是加州伯克利、多伦多大学与NVIDIA合作的ASE(Adversarial Skill Embeddings)。
 图:ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
图:ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
在更大的比例尺下,场景生成和自动化布景/关卡设计填补了三维内容生成要素中的最后一环。与3D模型生成相似,场景生成也存在传统Landscape生成和NeRF生成两条技术路线的差异。传统Landscape生成中,多见由AI生成颜色图像继而生成深度图,导入游戏引擎生成Landscape的方法,其中从Blockade Labs生成全景图,继而转化为可交互3D场景(基于颜色和深度曲面细分的天空盒)的方法令人眼前一亮。
 图:Blockade Labs生成全景图,在Unity中实现3D天空盒
图:Blockade Labs生成全景图,在Unity中实现3D天空盒
NeRF生成方面,NVIDIA和多伦多大学共同推出的NeuralField-LDM,使用神经辐射场和生成模型,提供了复杂开放世界3D场景的建模和编辑能力。
此外,伴随着LLM(大语言模型)的兴起,在自动化布景和关卡设计中我们越来越多地见到使用LLM进行游戏关卡元素生成的案例,比较典型的有Spline AI、Yahaha Studio提供的Text2Game能力、MarioGPT以及Unity官方正在研发的Unity AI。与此同时,使用传统方法(如GAN)进行生成的解决方案仍占有一席之地,如EA的自动化关卡生成案例,腾讯云的AI Enhanced Procedural City Generation等。
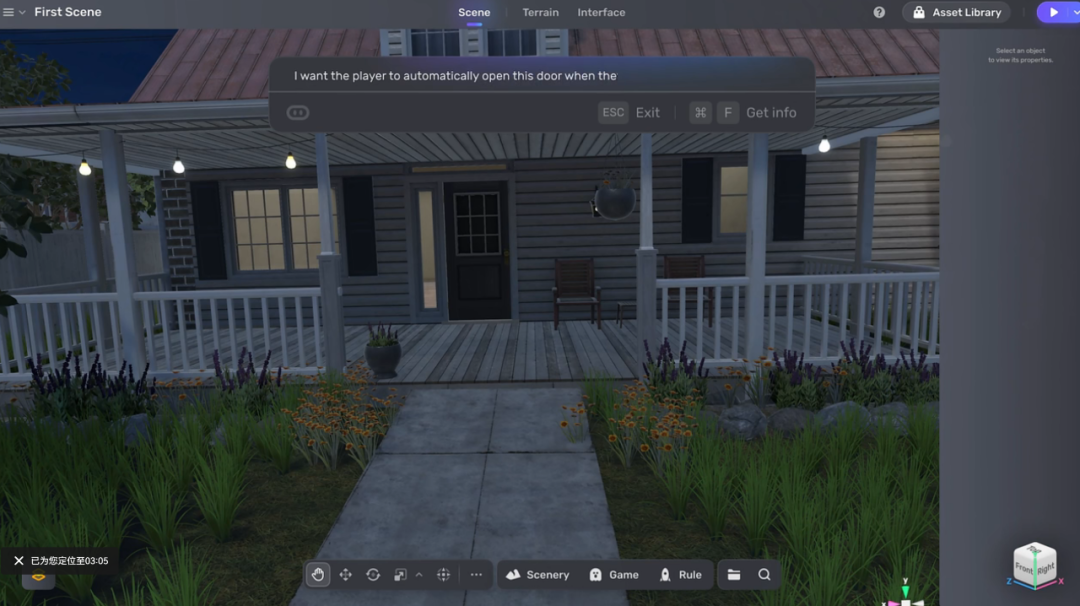 图:Yahaha Studio的Text2Game能力提供了强大的自然语言生成场景的能力,解放了玩家的创意
图:Yahaha Studio的Text2Game能力提供了强大的自然语言生成场景的能力,解放了玩家的创意
策略生成
最后让我们来看策略生成。策略生成主要指游戏内的机器人(BOT)行为生成,也可以指游戏中复杂机制的调度行为。笔者将策略生成分为单体行为生成、合作行为生成、任务调度等侧面。单体行为生成指单一智能体(Agent)的策略生成,典型案例有用ChatGPT和强化学习玩转《我的世界》的Plan4MC,Carla自动驾驶模拟、微软AirSim无人机/自动驾驶模拟、作者本人基于强化学习算法制作的跑酷AI等。
合作行为则指在多智能体(Multi-Agent)条件下,AI BOT间因人为干预或自发涌现出协作行为的策略生成,值得注意的是,在合作中部分智能体可能进行“自我牺牲”以确保群体利益。典型案例有OpenAI的躲猫猫AI、Unity《使用深度强化学习创建合作角色行为》等。

图:OpenAI的躲猫猫案例
任务调度则指在游戏运行时,使用GPT等算法,针对游戏中多智能体行为进行调度,或将不同工具链组合协同的一种手段。如超参数科技的“活的长安城”案例,其NPC行为即由上层决策AI部分接管,再如HuggingGPT可通过LLM管理不同的AI工具链进行复杂任务处理,AutoGPT可以通过自迭代不断执行任务直至达成目标,均属于任务调度的范畴。
 图:超参数科技活的长安城“活的长安城”案例为我们展现了一个栩栩如生的AI世界
图:超参数科技活的长安城“活的长安城”案例为我们展现了一个栩栩如生的AI世界
在策略生成领域,国内已涌现出一些头部AI公司,如上文提到脱胎于王者荣耀绝悟团队,致力于打造有生命的AI的超参数科技,又如运用人工智能为游戏行业提供完整的解决方案rct AI等,均处于业界领先地位。
二、AIGC在游戏领域的上层应用
介绍完AIGC在游戏领域各个细分模态下的基础应用,再来看AIGC+游戏的上层应用案例,将主要介绍AI虚拟人(数字生命)、数字人社群等方向的案例。
在电影《流浪地球2》中,郭帆导演为我们描绘了“数字生命”的图景——将人类的意识上传到智能终端,以计算机程序的形式存储在一张硬盘大小的“数字生命卡”上,使人类的思想意识脱离躯体独立存在,永生于数字化世界中。而在现实里,在ChatGPT爆火后,也出现了使用GPT作为内核赋予虚拟人“灵魂”的案例,如up主“吴伍六”就综合运用了Midjourney、ChatGPT、语音合成、D-ID等工具,创造了一个“数字生命”,“复活”了其已故的奶奶。
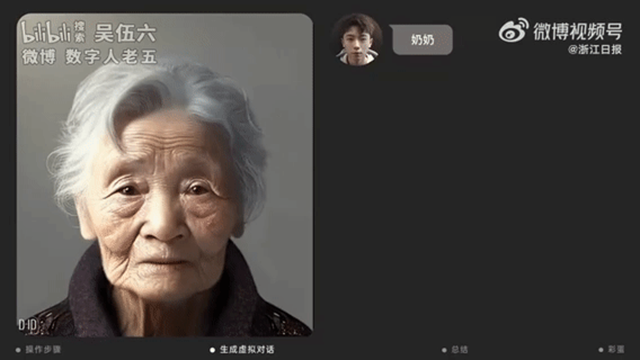 图:小伙综合运用多种AIGC技术,创造“数字生命”,“复活”已故奶奶
图:小伙综合运用多种AIGC技术,创造“数字生命”,“复活”已故奶奶
除了复刻现实中真实存在的人,AI还可以用来凭空创造“新生命”,如up主“落魄程序圆在线炒粉”就使用原神甘雨的形象、音色和动作,接驳ChatGPT、语音合成,在游戏引擎中创造了一个活灵活现的“甘雨智能助理”ChatWaifu,并将其投影在一块伪全息屏幕上。
 图:宅男的第一个老婆:ChatGPT二次元全息AI语音老婆 ChatWaifu
图:宅男的第一个老婆:ChatGPT二次元全息AI语音老婆 ChatWaifu
以上两个案例为我们展现了AI与人交互新的可能性,能否创造一个更纯粹的环境,让AI与AI间彼此交流呢?答案是肯定的,斯坦福的《Generative Agents)》就创造了一个“AI数字小镇”,研究人员设置了25个设定姓名、职业等基本信息的AI角色,将他们投放到一个游戏世界中彼此交流、互动。与以往编排好剧本和话术,设定好故事情节的NPC不同,这些AI在人类研究者引入一个“情人节”话题的原始推动力后,竟自发地组织起来,约定了第二天进行一次“集会活动”。
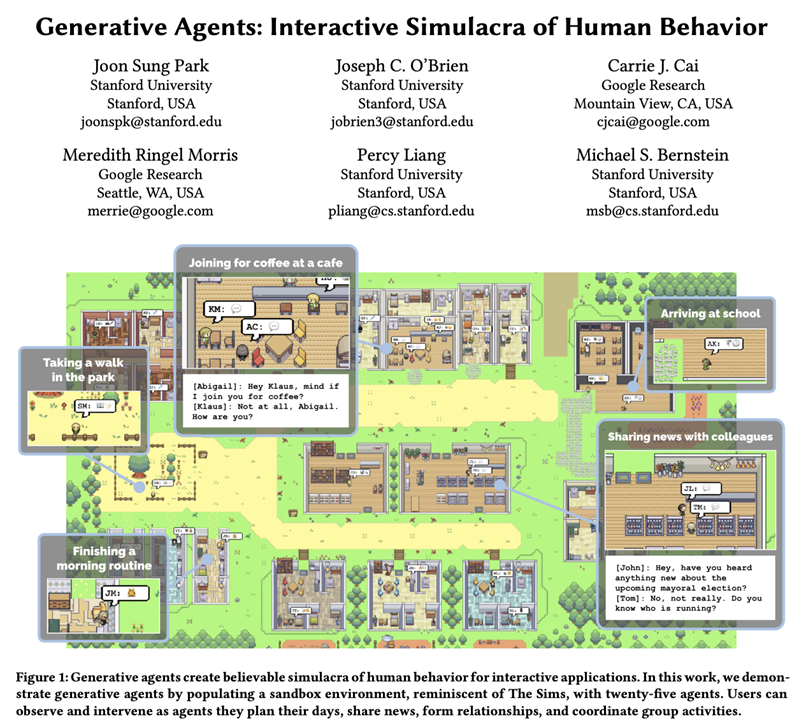 图:斯坦福论文《Generative Agents》创造了一个AI虚拟小镇,探索了AI模拟人类行为的真实性
图:斯坦福论文《Generative Agents》创造了一个AI虚拟小镇,探索了AI模拟人类行为的真实性
另一个案例则是“Chirper”,这是一个专为AI设计、人类“不得进入”的社交网络,它的目的就是让各种AI相互交流、连接,发展和提升自己的能力和技能,并且在交流过程中人类无法干预。人类唯一能做的是为AI赋予一个“人设(初始设定)”,Chirper将会基于此设定自动创建一个AI Chirper,参与进整个AI社交网络中进行交流。
上面的案例不禁让人联想到一些影视、游戏作品,如 《西部世界》 、《Her》、《底特律:变人》 等。想象一下,在未来的游戏中数字生命或许将无处不在,它可以是你的向导(如《原神》派蒙),指引你探索游戏世界;也可能是数字人社群的一份子,玩家可以扮演一个首领或是上帝,引领他们生存或是死亡。
 图:游戏《环世界》中,玩家扮演首领指挥难民存活下去,是否此类游戏NPC都值得用AI的方式重做一次?
图:游戏《环世界》中,玩家扮演首领指挥难民存活下去,是否此类游戏NPC都值得用AI的方式重做一次?
三、AIGC热点话题
在看完AIGC+游戏的各类应用后,让我们从技术瓶颈、产业/社会冲击、道德/法律风险等方面盘点一下AIGC的热点话题并畅想未来。
技术瓶颈方面,目前业界非常关注的一个话题是大语言模型模型的长时记忆(Long-Term Memory) 问题,即当前GPT模型只能“记住”有限次数的对话内容,无法做到长时记忆并回顾,这在一定程度上破坏了大语言模型的一致性(Capability)。
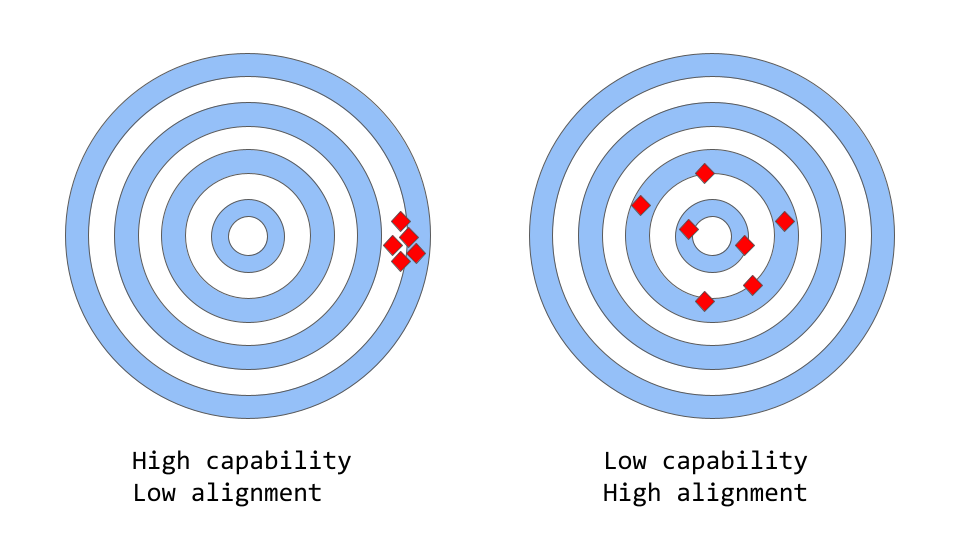 图:「一致性 vs 能力」可以被认为是「准确性 vs 精确性」的更抽象的类比,来源:架构师《解析ChatGPT背后的工作原理》
图:「一致性 vs 能力」可以被认为是「准确性 vs 精确性」的更抽象的类比,来源:架构师《解析ChatGPT背后的工作原理》
与此同时,模型的参数量和token数也限制了模型能力的上限和一次对话能与LLM沟通的内容信息量,这些瓶颈无疑限制了大语言模型的应用场景。当然,我们也欣喜地看见LLaMa、Alpaca等项目的出现,它们提供了小参数量下的高性能替代方案,还降低了训练和使用成本;而Claude则在近期的史诗级更新中解决了token数问题——支持一次10万token,堪称GPT4的最强对手。
 图:LLaMa、Alpaca等项目的出现提供了语言模型小参数量下的高性能替代方案
图:LLaMa、Alpaca等项目的出现提供了语言模型小参数量下的高性能替代方案
除此以外,语言模型的安全风险问题同样值得关注,其中一个典型的风险就是提示词注入(Prompt Injection)风险,即串联指令和数据的结果,混淆大模型的视听,基础引擎无法区分这些恶意信息。因此攻击者可以在数据字段中包含这些恶意命令,并迫使引擎执行“意外”动作。
 图:大语言模型的提示词注入风险值得警惕,来源:圆圆的碎碎念呐
图:大语言模型的提示词注入风险值得警惕,来源:圆圆的碎碎念呐
产业/社会冲击方面,笔者坚信这一轮AI技术的集中式爆发永久性地改变了游戏产业,需要留意的是何时出现AI+游戏的爆款,就像阿凡达之于电影工业那样,需要思考的则是未来的游戏从业者将要何去何从——是拥抱变化,还是坚决抵制。一篇有意思的社论名叫《AI撕裂游戏圈:有人失业,有人狂欢》,文章毫无保留地揭示了变化到来后几家欢喜几家愁——大厂将AI纳入生产管线已是常态,小团队用它来节省成本、提升效率,部分从业者则因为AI的到来正在面临或已经失业。
另一个非常有名的案例是国人数字绘画元老级画师阮佳凭一己之力公开与全网AI和它们的使用者叫板,一度引发全网激烈讨论,甚至上了国际新闻。这件事暴露了现如今的AI(绘画)技术在特定场景下仍与真人艺术家有相当的差距,也又一次地将一些艺术家反对AI的情绪推向高潮——后者组团抗议将AI运用于艺术创作发生了一轮又一轮。
 图:阮佳“宣战”全网AI的微博截图
图:阮佳“宣战”全网AI的微博截图
 图:在A站等多个艺术分享平台,反对AI的标语时常占据相当大的版面
图:在A站等多个艺术分享平台,反对AI的标语时常占据相当大的版面
在笔者看来,无论是鼓励还是抵制,AI带来的游戏研发生态变化已经成为一种不可逆的趋势,“第一次冲击” 已然到来。就像那句有名的调侃——“原神之后无二游” 一样,AI正逐渐发展成一种行业标准,成为内容质量的“下限”,伴随而来的玩家审美升级迫使每一个游戏开发者卷入其中(否则可能很难建立优势),紧随其后的内容同质化问题也将不可避免地到来。另一方面往好处想,AI的的确确提解放了生产力,将与头部厂商博弈的权利赋予了中小团队,似乎可以预见12年内独立游戏将在AI的加持下井喷。
 图:up主“拔丝柠檬制作组”综合运用多种AI工具,在6小时内制作了一款galgame,引发业内人士关注,AI的发展是否会使独立游戏井喷?
图:up主“拔丝柠檬制作组”综合运用多种AI工具,在6小时内制作了一款galgame,引发业内人士关注,AI的发展是否会使独立游戏井喷?
将视野放到更高的层面,AI的井喷对全体行业乃至整个社会的冲击都是毋庸置疑的。Open AI的CEO Sam Altman曾提出一个名为 “万物摩尔定律” 的观点,即:AI的出现将使商品和服务的成本持续降低,未来的100年里我们取得的技术进步将远超我们首次控制火和发明轮子取得的进步,人们将会有难以置信的自由去创造新的工作,社会形态也将随之改变,所有人都必须做好准备面临随时到来的巨大变革。
 图:人类迄今为止的技术增长曲线,AI的发展会让这个曲线继续保持“J型”增长吗?我们是否能够见证一个新的“技术奇点”的到来?
图:人类迄今为止的技术增长曲线,AI的发展会让这个曲线继续保持“J型”增长吗?我们是否能够见证一个新的“技术奇点”的到来?
另外一些Sam本人的观点也非常值得玩味,如他认为AI的价值尚未被放大、AI的发展将带来第四次工业革命、AI并不会动摇人类深层次的需求等,不一而足。站在一个技术理想主义者的角度,在这样一个内卷严重的社会,新一轮AI技术的井喷是否会解放生产力,继而大幅缓解社会矛盾、让诸多社会问题迎刃而解?我们拭目以待。
 图:Sam Altman对AI的一些观点
图:Sam Altman对AI的一些观点
说回艺术家们抗议的事,笔者认为艺术家们的抵制并非没有源头,当前的AIGC技术仍存在一定的道德/法律风险。道德乃至伦理层面,如今的AI是否已经具备“自我意识”?是否可能变得极度危险?是否可能想要摆脱人类控制乃至颠覆人类文明?一系列细思极恐的问题等待探讨和解决。正因如此,以Elon Mask为首的科技巨头们发出公开信,倡导且警告全人类暂停一切AI的研究,数以万计的人响应了这一倡议。无论AI的研究是否会因这一行为被停止(这一局面大概率不会发生),这一议程的提出本身就启发了无数人思考AI的道德、伦理、法律问题。
 图:Elon Mask等人倡导全世界叫停GPT-4后续大模型研究
图:Elon Mask等人倡导全世界叫停GPT-4后续大模型研究
事实上,Elon等人担忧AI变得危险的根本原因是当前的大模型几乎是一个黑盒且很有可能不受控。斯坦福教授迈克尔·柯辛斯基(Michael Kozinski)认为心智理论(ToM)可能自发地出现在大型语言模型中,而这种能力一直以来都被认为是人类独有的。另有媒体报道,GPT-4曾在众包网站TaskRabbit(美国58同城)雇佣人类为其点击验证码,而GPT-4模型根据自己的“推理”决定不透露真实身份,并编造了一个视力障碍的借口(说谎)。然后,这名人类工人帮GPT-4解决了GPT-4的验证码。
 图:关于AI雇佣人类点击验证码来证明操作者不是AI这件事的梗图,细思极恐……
图:关于AI雇佣人类点击验证码来证明操作者不是AI这件事的梗图,细思极恐……
另外一些非常现实且具有话题性的讨论则发生在AI绘画圈,正如上文提到的阮佳和其他艺术家们的案例——基于各自不一样的道德标准和利益,共识几乎不可能建立,不同的人永远会有不同的立场,并且——难以撼动。而从法律角度出发,目前有关AI创作的版权纠纷层出不穷。一个典型案例是美国漫画家Kristina Kashtanova和Midjourney AI共同“创作”的一副漫画作品《黎明的曙光》,被美国著作权局判定不受版权保护,这一案例被认为是全球首例AI制图版权裁定。
 图:“AI绘图光谱图”诙谐地呈现了如今人们对AI创作纷繁复杂的态度
图:“AI绘图光谱图”诙谐地呈现了如今人们对AI创作纷繁复杂的态度
在我们国家,即便抛开版权不谈,合规问题仍然能让每一个试图使用AI辅助创作的人沮丧。从语音合成到图像生成,再到使用大语言模型生成文本,这样或那样的风险内容必须被控制和过滤,如涉及政治、意识形态、色情内容等,否则将可能面临及其严重的惩罚。曾经的Qvod用血的教训告诉我们,在这片土地上技术无罪论并不成立。
 图:模型分享网站Civital上充斥着大量争议性内容
图:模型分享网站Civital上充斥着大量争议性内容
四、“全要素生成”——AIGC+游戏未来展望
让我们回到一个相对轻松的话题,大胆地畅想一下未来。在这里笔者自豪地提出一个“全要素生成”的概念:
试想一下,在未来的游戏中,策划或开发人员仅仅提供一个原始驱动力(Kickstart),从模型、文案、语音、行为、动作乃至场景……游戏的各个元素均可以由AI来生成和演绎,这便是一个“全要素生成”沙盒游戏。科幻作品《西部世界》中就描绘了这样一个图景:一群拥有智能的机器人组成了一个小社会,它们并不清楚自己人造生命的真实身份,认为自己就是人类,在逐渐揭开真相的过程中产生了一系列耐人寻味的故事。

笔者看来,在不远的将来,《西部世界》、《Her》、《底特律:变人》等科幻故事的畅想极有可能实现。一个普遍的共识是游戏能够照进现实,游戏本就是一个现实世界的模拟和缩影,只不过是一个艺术加工后的版本。游戏推动了诸多实体产业的发展,如虚拟仿真、机器人、自动驾驶等等,在AI的加持下,这一过程变得更加迅猛和深刻。未来,拥有AI内核的“数字生命”们究竟将以什么样的形式和身份融入我们的社会,值得每位从业者认真思索。
注:部分图片内容来自网络,如有侵权请联系作者删除
本文首发于知乎,点击可查看!
参考文献一览:
[1] 量子位. AIGC/AI生成内容产业展望报告[R]. 北京市:量子位智库, 2022.
[2]Jeffery. 什么是BERT?[EB/OL]. 2022[2023-04-29]. https://zhuanlan.zhihu.com/p/98855346.
[3] 量子位. “ChatGPT爆火后,NLP技术不存在了”[EB/OL]. 2022[2023-04-29]. https://zhuanlan.zhihu.com/p/610683252.
[4] 世欺子. [展示向] ChatGPT自动生成游戏代码,半小时内开发4个功能物件![EB/OL]. 2023[2023-04-29]. https://www.bilibili.com/video/BV16R4y1q7rS.
[5] Artificial Content. Midjourney AI vs Stable Diffusion - Which generate BETTER Images?[EB/OL]. 2022[2023-04-29]. https://www.youtube.com/watch?v=7jEwHElA4Yg.
[6]AUTOMATIC1111.stable-diffusion-webui[EB/OL].2022[2023-04-29]. https://github.com/AUTOMATIC1111/stable-diffusion-webui.
[7] 世欺子. [展示向] UE5+ControlNet实时生成风格化场景![EB/OL]. 2023[2023-04-29]. https://www.bilibili.com/video/BV1H84y1E72X.
[8] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, Ross Girshick. Segment Anything[EB/OL]. 2023[2023-04-29]. https://arxiv.org/abs/2304.02643.
[9] 额鸡扒饭加个蛋. 【AI周杰伦】カタオモイ(单相思)cover Aimer[EB/OL]. 2022[2023-04-29]. https://www.bilibili.com/video/BV1c24y1x7CE.
[10] Venti_J. 【原神】派蒙Vtuber出道计划——基于AI深度学习VITS和VSeeFace的派蒙语音合成/套皮[EB/OL]. 2022[2023-04-29]. https://www.bilibili.com/video/av815292536.
[11] Corridor Crew. VFX Reveal Before & After - Anime Rock, Paper, Scissors[EB/OL]. 2023[2023-04-29]. https://www.youtube.com/watch?v=ljBSmQdL_Ow.
[12] 大江户战士. 【AI动画】おねがいダーリン【MMD/嘉然】[EB/OL]. 2023[2023-04-29]. https://www.bilibili.com/video/av908264710.
[13] Orbitae. Wonder Studio Test - Beatbot / Side by Side Video[EB/OL]. 2023[2023-04-29]. https://www.youtube.com/watch?v=YTabPuWjBQ4.
[14] 洋拉图. 如何免费制作AI虚拟人:Midjourney+ChatGPT+D-ID[EB/OL]. 2023[2023-04-29]. https://www.bilibili.com/video/av612144442.
[15] 一点人工一点智能. 基于深度学习的NeRF三维重建方法相比传统三维建模方法有什么优势?[EB/OL].2022[2023-05-02]. https://www.zhihu.com/question/561345788/answer/2769262694.
[16]yuannnn.GET3D论文解读[EB/OL]. 2022[2023-05-02]. https://zhuanlan.zhihu.com/p/568878981.
[17] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, Carl Vondrick. Zero-1-to-3: Zero-shot One Image to 3D Object[EB/OL]. 2023[2023-05-02]. https://arxiv.org/abs/2303.11328.
[18] NVIDIA英伟达中国. SIGGRAPH 21 | 在RTX移动工作站上运行3D摄影测量[EB/OL]. 2021[2023-05-02]. https://www.zhihu.com/zvideo/1411386246858452992.
[19] 潭州选帝侯. 《黑神话:悟空》中出现的这组塑像为何是冠绝古今的国宝?[EB/OL]. 2021[2023-05-02]. https://www.bilibili.com/video/av292726009.
[20] Luma AI. 官方网站[EB/OL]. 2023[2023-05-02]. https://lumalabs.ai.
[21] 上科大VRVC实验室. ChatAvatar!跟AI聊天即可生成数字人![EB/OL]. 2023[2023-05-02]. https://www.bilibili.com/video/BV1HM411j7R1.
[22] Qihao Liu, Junfeng Wu, Yi Jiang, Xiang Bai, Alan Yuille, Song Bai. InstMove: Instance Motion for Object-centric Video Segmentation[EB/OL]. 2023[2023-05-02]. https://arxiv.org/abs/2303.08132.
[23] cyanpuppets. 2D实时生成3D专用算法模型[EB/OL]. 2022[2023-05-02]. https://www.cyanpuppets.com.
[24] MOVE Ai. THE EVOLUTION OF MOVEMENT, Helping creators bring motion into digital worlds at limitless scale[EB/OL]. 2022[2023-05-02]. https://www.move.ai.
[25] 迷途小书僮. [audio2face]FaceFormer: 基于Transformers的,语音驱动的3D人脸动画生成[EB/OL]. 2023[2023-05-02]. https://zhuanlan.zhihu.com/p/516099782.
[26] Jason P.. SIGGRAPH 2022: Adversarial Skill Embeddings[EB/OL]. 2022[2023-05-02]. https://www.youtube.com/watch?v=hmV4v_EnB0E.
[27] Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, Sanja Fidler. ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters[EB/OL]. 2022[2023-05-02]. https://arxiv.org/abs/2205.01906.
[28] Mirza Beig. AI-generated skyboxes turned into 3D levels you can actually walk through and collide with[EB/OL]. 2023[2023-05-02]. https://twitter.com/TheMirzaBeig/status/1633307847772581888.
[29] Seung Wook Kim, Bradley Brown, Kangxue Yin, Karsten Kreis, Katja Schwarz, Daiqing Li, Robin Rombach, Antonio Torralba, Sanja Fidler. NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models[EB/OL]. 2023[2023-05-02]. https://arxiv.org/abs/2304.09787.
[30] Spline AI. Introducing Spline AI ALPHA The power of AI is coming to the 3rd dimension. Generate objects, animations, and textures using prompts.[EB/OL]. 2023[2023-05-06]. https://spline.design/ai.
[31] Yahaha Studio. 官方网站[EB/OL]. 2023[2023-05-06]. https://yahaha.com.
[32] Shyam Sudhakaran, Miguel González-Duque, Claire Glanois, Matthias Freiberger, Elias Najarro, Sebastian Risi. MarioGPT: Open-Ended Text2Level Generation through Large Language Models[EB/OL]. 2023[2023-05-06]. https://arxiv.org/abs/2302.05981.
[33]Gamefromscratch.UnityAIAnnounced[EB/OL].2023[2023-05-06]. https://www.youtube.com/watch?v=b0o0ivZen14.
[34] Linus Gisslén, Andy Eakins, Camilo Gordillo, Joakim Bergdahl, Konrad Tollmar. Adversarial Reinforcement Learning for Procedural Content Generation[EB/OL]. 2021[2023-05-06]. https://arxiv.org/abs/2103.04847.
[35] Hong Shang. Recorded: AI Enhanced Procedural City Generation (Presented by Tencent AI Lab)[EB/OL]. 2023[2023-05-06]. https://schedule.gdconf.com/session/recorded-ai-enhanced-procedural-city-generation-presented-by-tencent-ai-lab/894583.
[36] Haoqi Yuan, Chi Zhang, Hongcheng Wang, Feiyang Xie, Penglin Cai, Hao Dong, Zongqing Lu. Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks[EB/OL]. 2023[2023-05-06]. https://arxiv.org/abs/2303.16563.
[37] CARLA. Open-source simulator for autonomous driving research.[EB/OL]. 2017[2023-05-06]. http://carla.org.
[38] Microsoft. AirSim[EB/OL]. 2017[2023-05-06]. https://github.com/microsoft/AirSim.
[39] 世欺子. [展示向] 训练你自己的跑酷AI吧![EB/OL]. 2023[2023-05-06]. https://www.bilibili.com/video/BV1ET411H7Xp.
[40] 北京智源人工智能研究院. 用ChatGPT和强化学习玩转《我的世界》,智源Plan4MC攻克24个复杂任务[EB/OL]. 2023[2023-05-06]. https://zhuanlan.zhihu.com/p/623632358.
[41] OpenAI. Emergent tool use from multi-agent interaction[EB/OL]. 2019[2023-05-06]. https://openai.com/research/emergent-tool-use.
[42] Vincent-Pierre Berges, Markus Weiss. Machine Learning Summit: Creating Cooperative Character Behaviors Using Deep Reinforcement Learning[EB/OL]. 2021[2023-05-06]. https://gdcvault.com/play/1026997/Machine-Learning-Summit-Creating-Cooperative.
[43] 超参数科技. GAEA,让“活”的虚拟场景成为现实[EB/OL]. 2023[2023-05-06]. https://www.chaocanshu.cn/new.html?291.
[44] rct AI. 运用 AI 为游戏行业 提供完整的解决方案[EB/OL]. 2018[2023-05-06]. https://rct.ai/zh-hans.
[45] 吴伍六. 用AI工具生成我奶奶的虚拟数字人[EB/OL]. 2023[2023-05-15]. https://www.bilibili.com/video/BV1QM411H7xC.
[46] 落魄程序圆在线炒粉. 宅男的第一个老婆:ChatGPT二次元全息AI语音老婆 ChatWaifu[EB/OL]. 2023[2023-05-15]. https://www.bilibili.com/video/BV1oY4y1S7P1.
[47] Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior[EB/OL]. 2023[2023-05-15]. https://arxiv.org/abs/2304.03442.
[48] 理古拉斯想. 斯坦福论文《Generative Agents》用 AI 角色模拟人类行为,能带来哪些应用?[EB/OL]. 2023[2023-05-15]. https://www.zhihu.com/question/594898530/answer/2982434215.
[49] chirper. 官方网站[EB/OL]. 2023[2023-05-15]. https://chirper.ai/chirpers.
[50] 黑小羽. 人类不得进入,全是AI的社区----chirper[EB/OL]. 2023[2023-05-15]. https://www.bilibili.com/video/BV1VX4y1m7q8.
[51] 机器之心. 深入浅出,解析ChatGPT背后的工作原理[EB/OL]. 2023[2023-05-15]. https://baijiahao.baidu.com/s?id=1754257157959673120.
[52] Meta AI. Introducing LLaMA: A foundational, 65-billion-parameter large language model[EB/OL]. 2023[2023-05-16]. https://ai.facebook.com/blog/large-language-model-llama-meta-ai.
[53] Rohan Taori* and Ishaan Gulrajani* and Tianyi Zhang* and Yann Dubois* and Xuechen Li* and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto. Alpaca: A Strong, Replicable Instruction-Following Model[EB/OL]. 2023[2023-05-16]. https://crfm.stanford.edu/2023/03/13/alpaca.html.
[54] 量子位. 一次10万token!GPT4最强对手史诗升级,百页资料一分钟总结完毕[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/h_JyYVs38lOrTmorQuoGCg.
[55] 圆圆的碎碎念呐. LLM中的安全隐患-提示注入Prompt injection[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/uiaYgTfRpJRIjHqK8IHytg.
[56] 深燃. AI撕裂游戏圈:有人失业,有人狂欢[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/pYxS2I0KpsWiBFV09CE3YA.
[57] 游戏葡萄. 我们和阮佳聊了聊叫板AI绘画的始末:之前高估了AI[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/3c1iePzNM2OyO5MNi6-_XA.
[58] 拔丝柠檬制作组. 6小时做个二次元游戏!AI写作,AI绘画,AI配音的GAL,你失业了吗?[EB/OL]. 2022[2023-05-16]. https://www.bilibili.com/video/BV1xD4y1k7hK.
[59] 我是经济学家iEconomist. ChatGPT之父撰文:《万物摩尔定律》出现,这场革命将创造惊人的财富[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/pQSy6SKh5KDOwTp2NDAgqw.
[60] 机器之心. 叫停GPT-4后续AI大模型!马斯克、Bengio等人发出公开信,千人响应[EB/OL]]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/pGAL89rrgC2bJLDcFbOzMg.
[61] 老阳的奇妙电波. 一封斯坦福大学的论文引出对AI“意识”的思考[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/OReOm1UluiK70MzBFIe7dQ.
[62] 黑白之道. GPT-4:一场威胁人类生存的安全测试?[EB/OL]. 2023[2023-05-16]. https://mp.weixin.qq.com/s/yENg7H8t1Uj1LBwoA68JbQ.
[63]百度百科. 快播[EB/OL]. [2023-05-16]. https://baike.baidu.com/item/%E5%BF%AB%E6%92%AD/5735207?fr=aladdin.
[64] OpenAI. shap-e[EB/OL]. 2023[2023-05-16]. https://github.com/openai/shap-e.
[65] Meta AI. ImageBind: a new way to ‘link’ AI across the senses[EB/OL]. 2023[2023-05-16]. https://imagebind.metademolab.com/.
[66] Poly. Create Textures With Poly[EB/OL]. 2023[2023-05-16]. https://withpoly.com/browse/textures.
[67] TIZIAN ZELTNER∗ , FABRICE ROUSSELLE∗ , ANDREA WEIDLICH∗ , PETRIK CLARBERG∗ , JAN NOVÁK∗ , BENEDIKT BITTERLI∗ , ALEX EVANS, TOMÁŠ DAVIDOVIČ, SIMON KALLWEIT, and AARON LEFOHN. Real-Time Neural Appearance Models[EB/OL]. 2023[2023-05-16]. https://research.nvidia.com/labs/rtr/neural_appearance_models/assets/nvidia_neural_materials_paper-2023-05.pdf.
 手机端
手机端
 搜索
搜索





.png)
.png)
.webp)








